NGRPO: Learning from Homogeneous Failures
NGRPO: Negative-enhanced Group Relative Policy Optimization
Gongrui Nan, Siye Chen, Jing Huang, Mengyu Lu, Dexun Wang, Chunmei Xie, Weiqi Xiong, Xianzhou Zeng, Qixuan Zhou, Yadong Li, Xingzhong Xu
NGRPO studies a precise failure mode in GRPO-style RLVR: when every response in a sampled group is wrong, reward normalization produces zero advantage and the model receives no gradient from the hardest prompts. The paper turns that dead zone into an exploration signal by adding a virtual maximum-reward sample to advantage normalization, then stabilizes the extra pressure with asymmetric clipping.
In Brief
- 1
The central object is not reward design in general, but the zero-gradient pathology of homogeneous incorrect groups.
- 2
A single virtual max-reward sample shifts the group mean upward, giving every wrong rollout a calibrated negative advantage.
- 3
Asymmetric clipping makes positive updates looser and negative updates tighter, balancing exploration with stability.
- 4
The strongest empirical message is that learning from collective failure lifts both low-k accuracy and high-k exploration on math reasoning.
Problem
GRPO samples a group of responses for the same prompt and normalizes their rewards inside the group. This works when a group contains both correct and incorrect trajectories, but collapses to zero advantage when all rewards are identical. Homogeneous correct groups are less concerning; homogeneous incorrect groups are exactly where the model needs pressure to explore. DAPO filters these groups out, while PSR-NSR keeps negative samples with fixed advantages but can collapse when the negative signal is too strong.
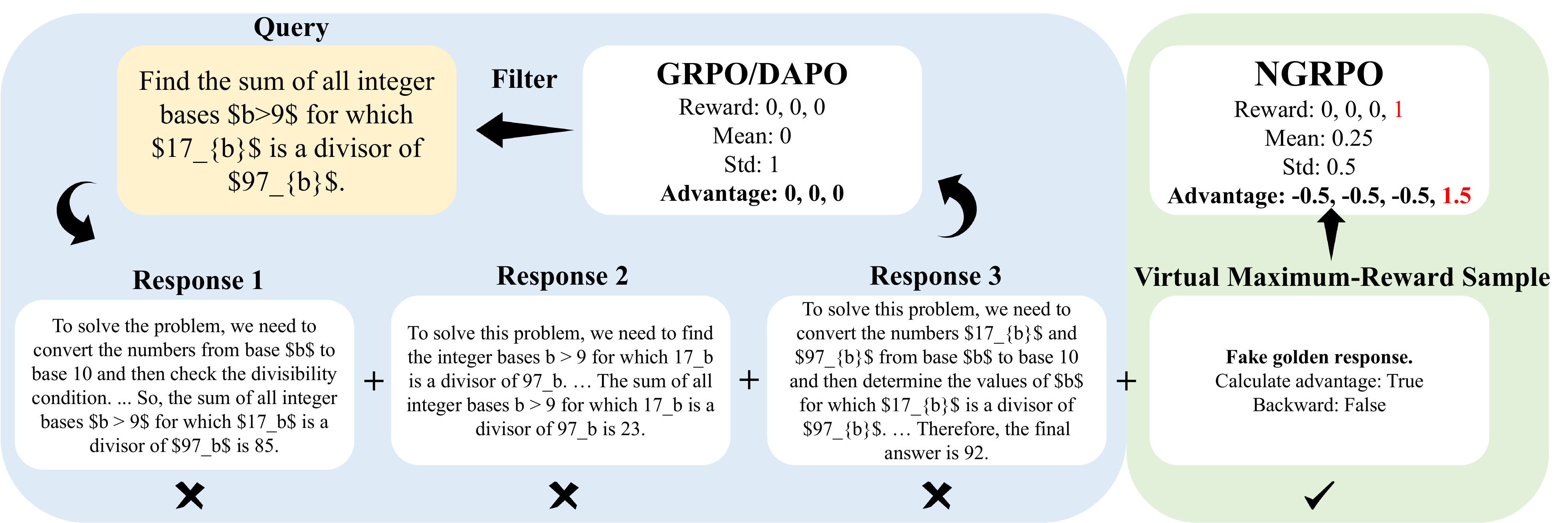
Mechanism
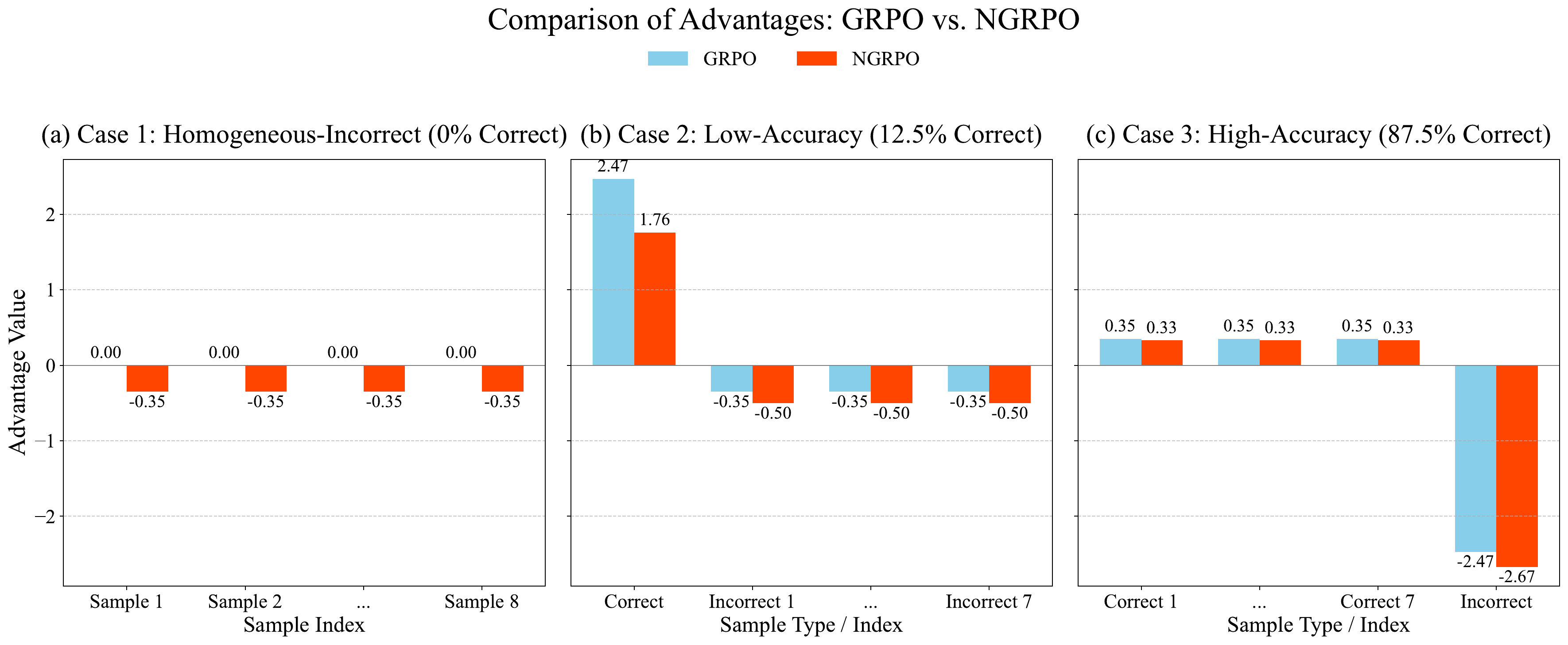
NGRPO adds a virtual sample with reward r_max only for computing group statistics. The real rollouts are still the only optimized samples, but their normalized advantages are now computed against the augmented reward set. In an all-wrong group, this produces a uniform negative advantage instead of zero. In mixed groups, it dampens positive advantages and strengthens negative ones more when group accuracy is low, then becomes less intrusive when the group is already mostly correct.
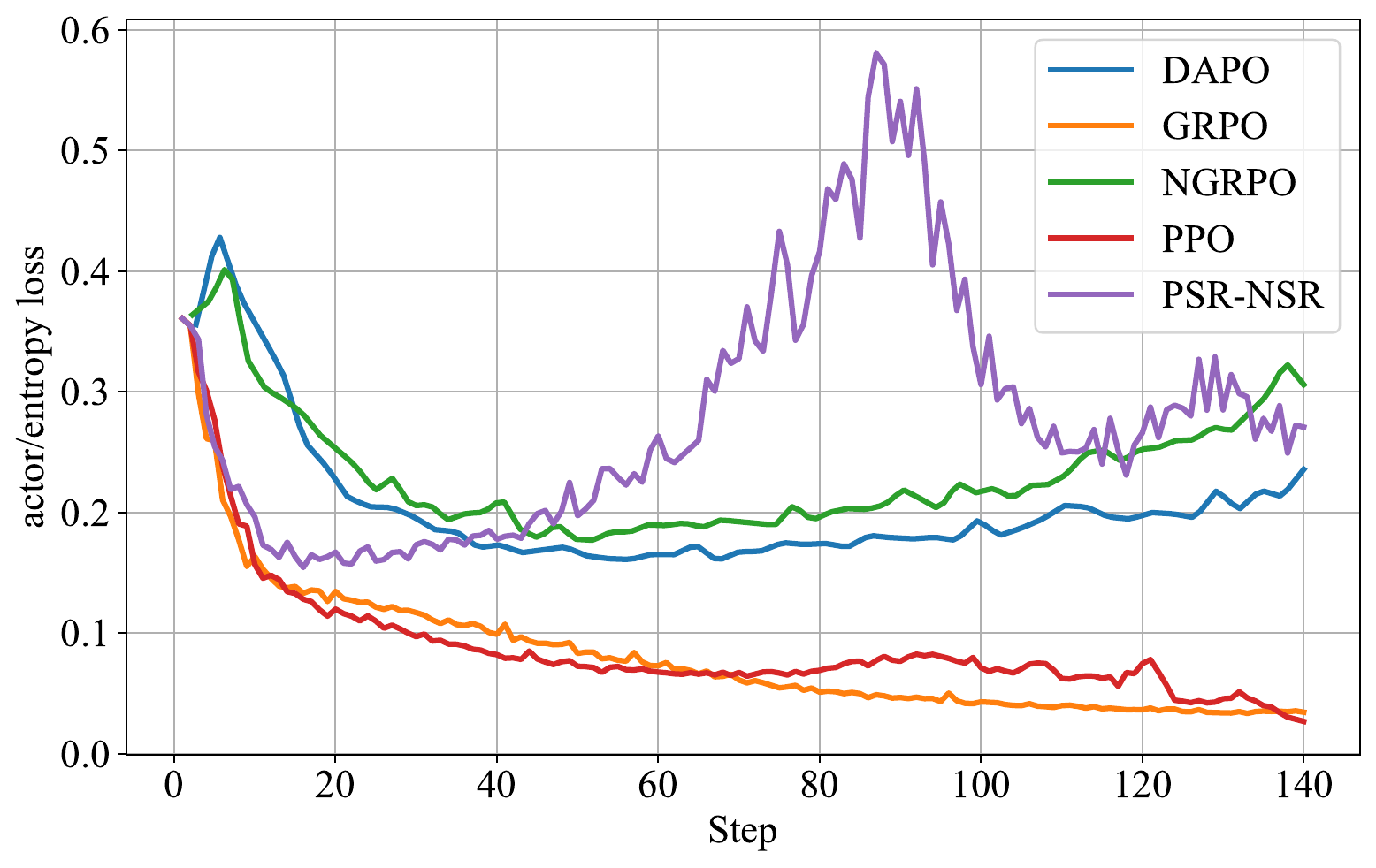
Stability
The virtual reward makes the sum of advantages negative, which increases exploratory pressure. NGRPO therefore changes the PPO-style clipping interval: positive advantages use a wider upper bound, while negative advantages use a tighter lower bound. The paper uses epsilon_pos = 0.24 and epsilon_neg = 0.16, following the intuition that correct trajectories can be amplified more freely while incorrect trajectories should be penalized with tighter control.
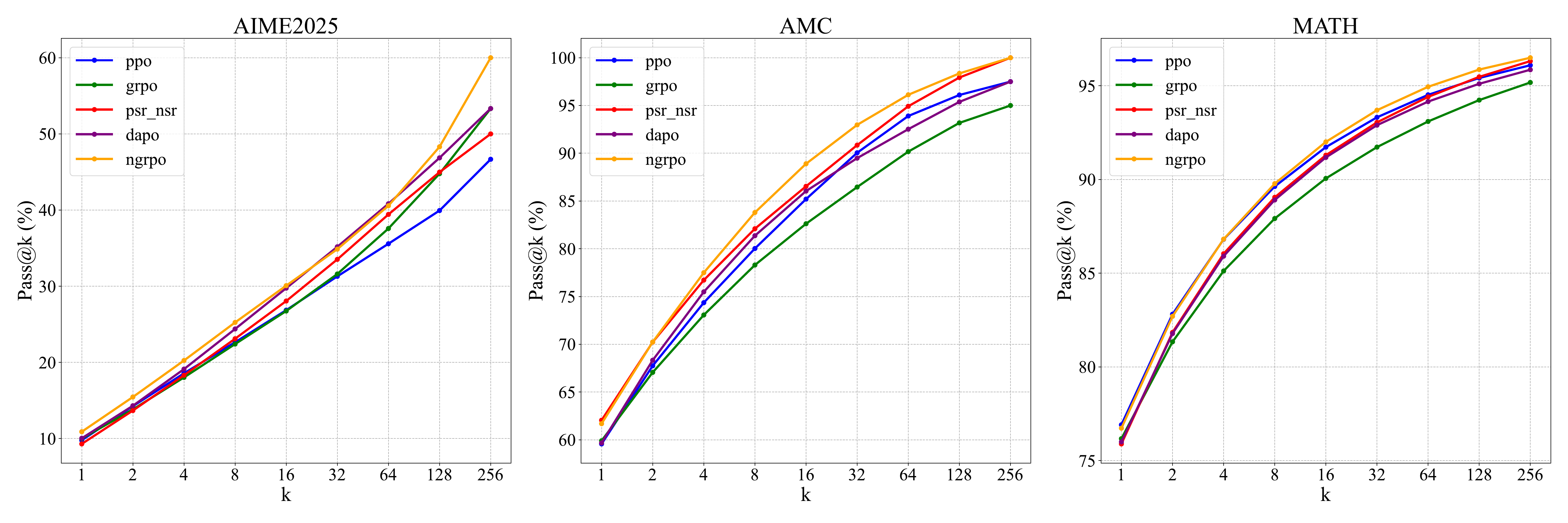
Evidence
On Qwen2.5-Math-7B trained on MATH, NGRPO reports the best Pass@k AUC on AIME2025, AMC, and MATH among PPO, GRPO, PSR-NSR, DAPO, and NGRPO. The AIME2025 AUC rises to 31.28, above DAPO's 30.27 and GRPO's 28.33; AMC rises to 86.09; MATH reaches 90.31. Ablations show that the virtual reward gives a substantial gain, asymmetric clipping adds stability, and keeping homogeneous incorrect groups is necessary for the full effect.