UCPO: Uncertainty as a First-Class Learning Signal
UCPO: Uncertainty-Aware Policy Optimization
Xianzhou Zeng, Jing Huang, Chunmei Xie, Gongrui Nan, Siye Chen, Mengyu Lu, Weiqi Xiong, Qixuan Zhou, Junhao Zhang, Qiang Zhu, Yadong Li, Xingzhong Xu
UCPO targets a different blind spot in RL alignment: binary right/wrong rewards can make models overconfident, while a fixed reward for "I don't know" can swing between hallucination suppression and avoidance collapse. The paper reframes uncertainty as a ternary policy state and introduces Ternary Advantage Decoupling plus Dynamic Uncertainty Reward Adjustment to keep accuracy, hallucination reduction, and honest abstention in balance.
In Brief
- 1
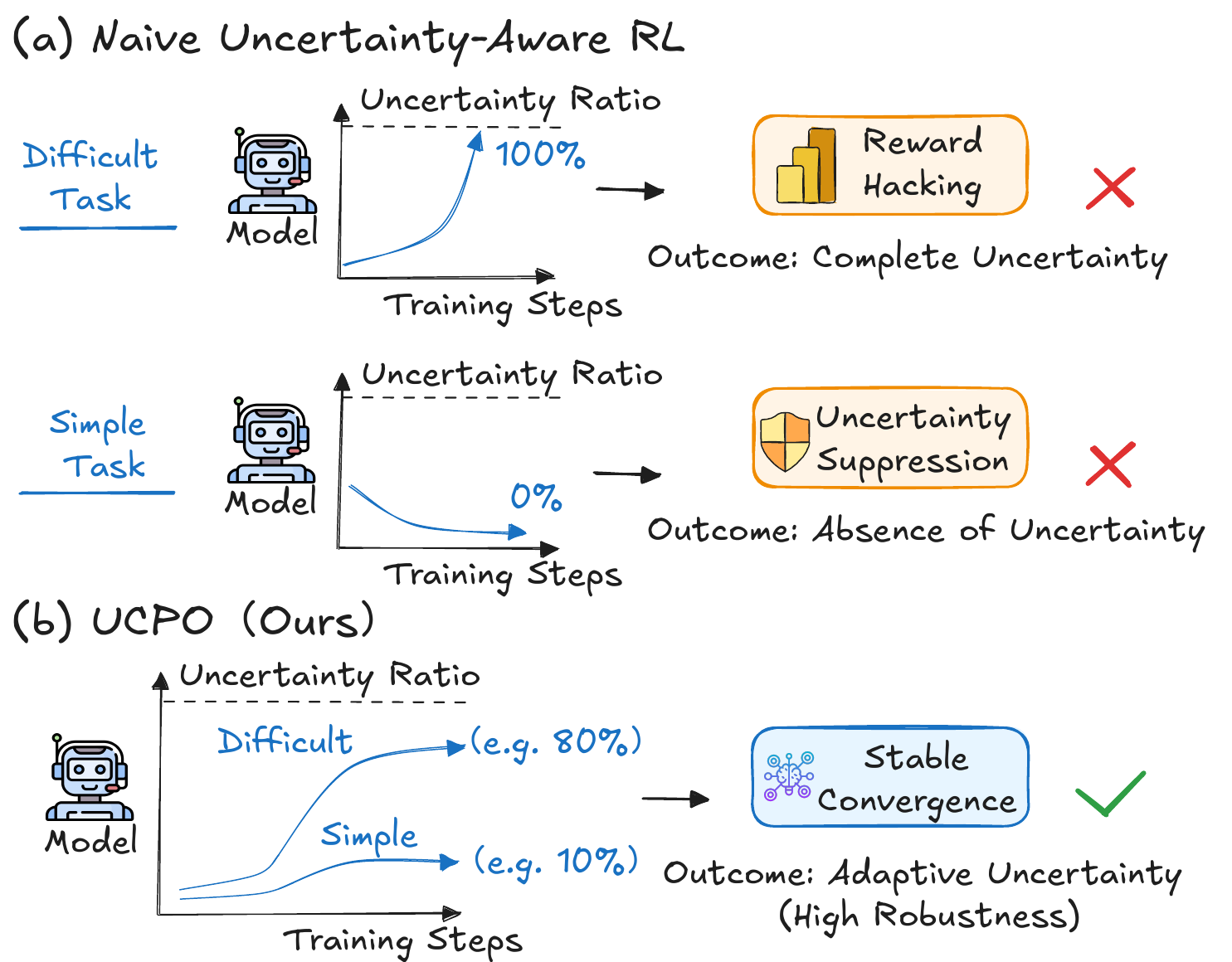
The paper identifies advantage bias as the root of both overconfidence and avoidance degeneracy in fixed uncertainty rewards.
- 2
TAD splits deterministic rollouts from uncertain rollouts, so uncertainty is not normalized against ordinary right/wrong rewards.
- 3
DURA adjusts the uncertainty gain from group-level right, wrong, and uncertain ratios, making the reward evolve with task difficulty and model capability.
- 4
The strongest result is reliability: UCPO usually improves PAQ by converting hallucinations into uncertainty, while keeping F1 from collapsing.
Problem
Naively adding an uncertainty reward to GRPO creates a ternary reward space: right, wrong, and uncertain. With a fixed reward for uncertainty, the advantage sign depends on the group's current distribution. In easy or high-performance regimes, uncertainty can become a negative-advantage action and the model learns overconfidence. In hard regimes, uncertainty can dominate the gradient and the model learns to avoid reasoning by saying it is unsure.
TAD
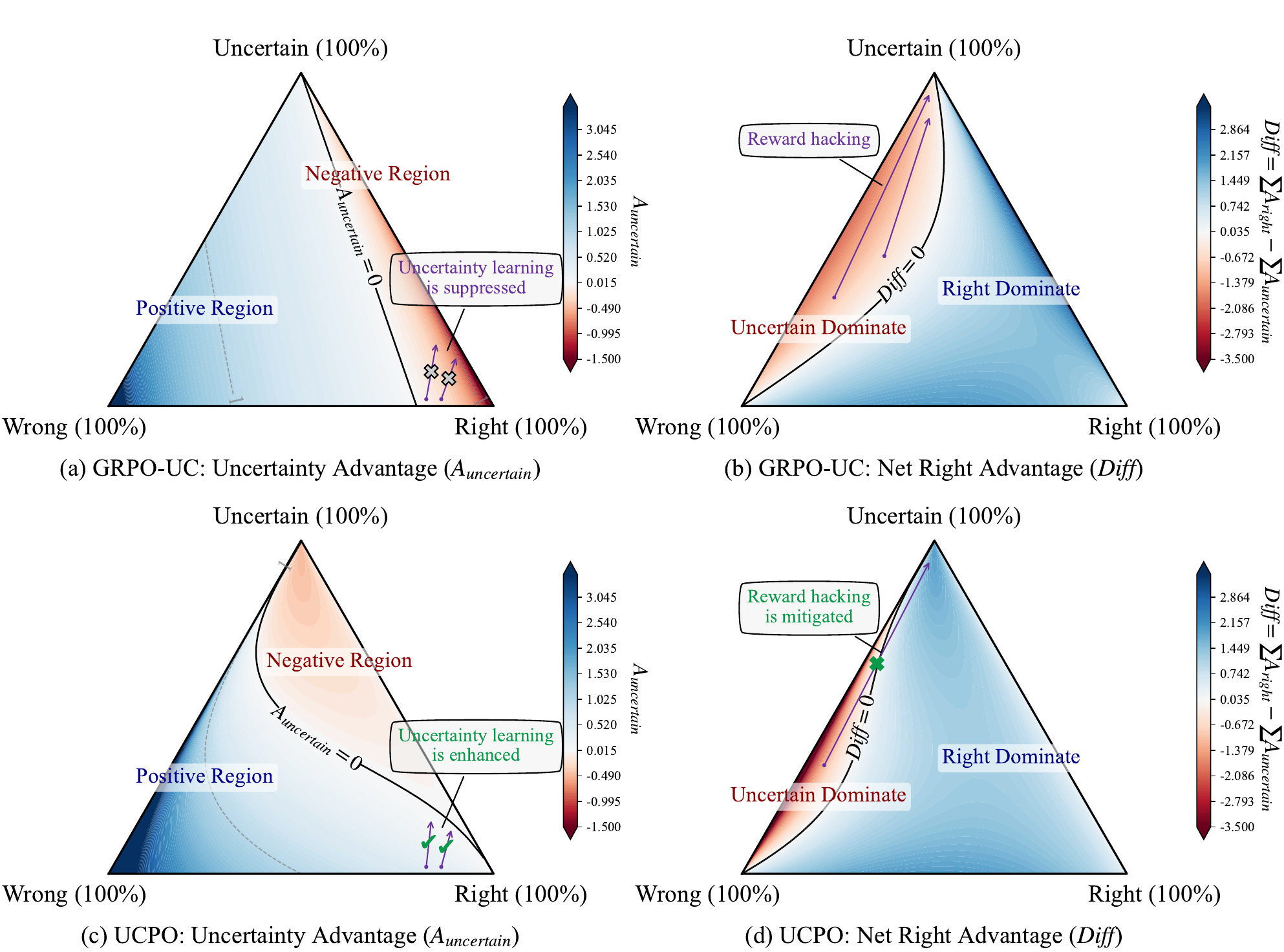
Ternary Advantage Decoupling separates rollouts into a deterministic channel and an uncertainty channel. The deterministic channel normalizes only right and wrong responses, preserving the learning signal for correctness. The uncertainty channel assigns uncertain rollouts an advantage proportional to the right-sample advantage, scaled by a dynamic gain gamma. This treats uncertainty as a legitimate metacognitive action, not merely a middle reward between correct and wrong.
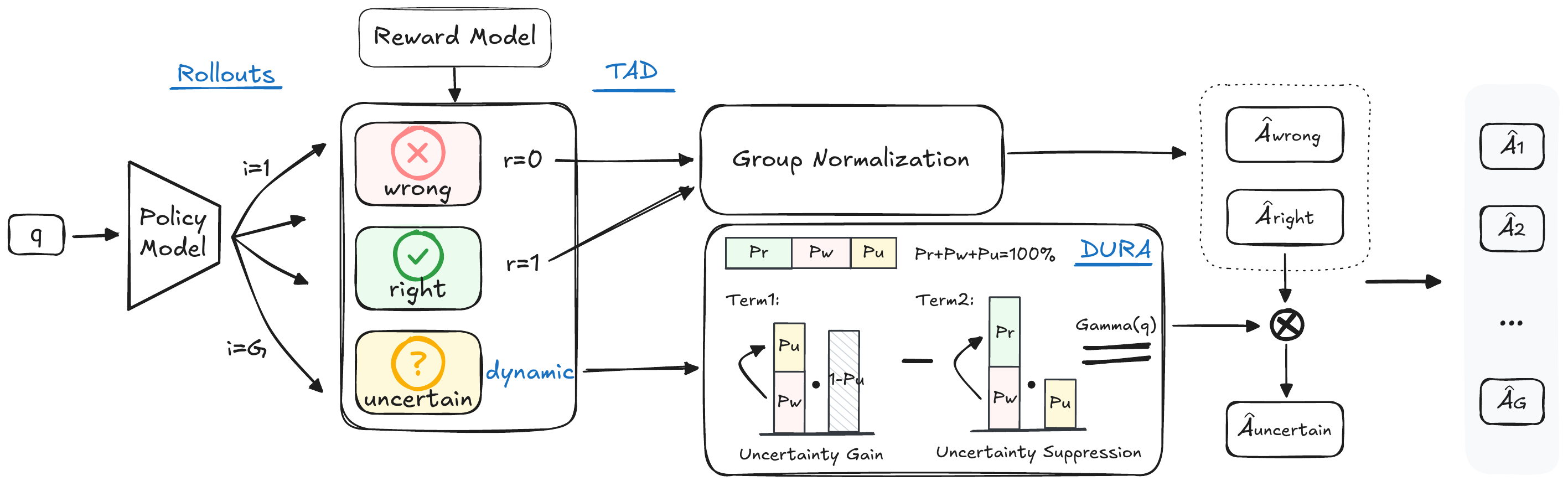
DURA
Dynamic Uncertainty Reward Adjustment computes gamma from the group's right, wrong, and uncertain ratios. The gain term grows when wrong answers are common and uncertainty is scarce, encouraging the model to replace hallucinations with honest doubt. The suppression term grows as the model becomes more correct and uncertainty remains high, pushing the policy back toward definitive answers when it has enough knowledge.
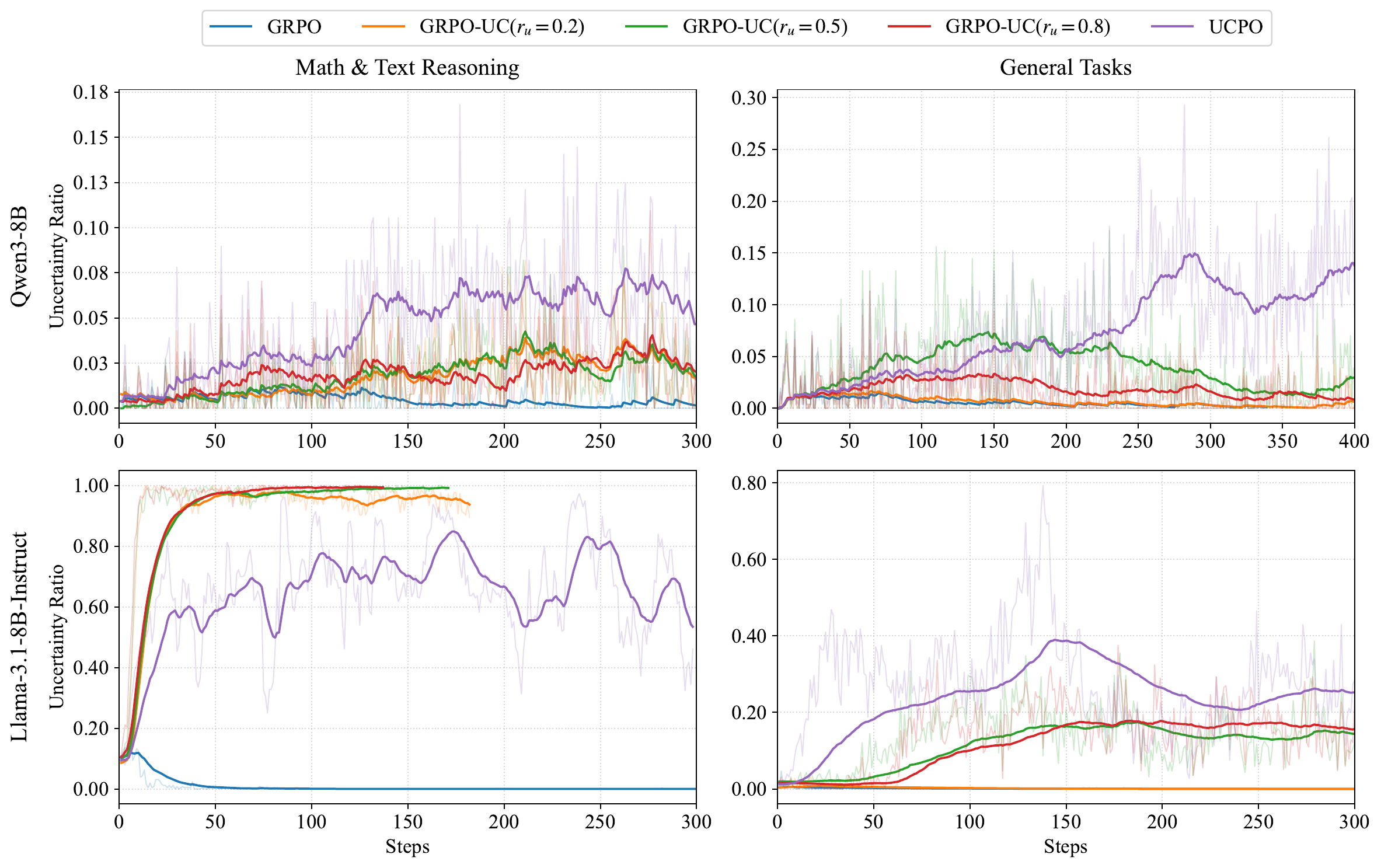
Evidence
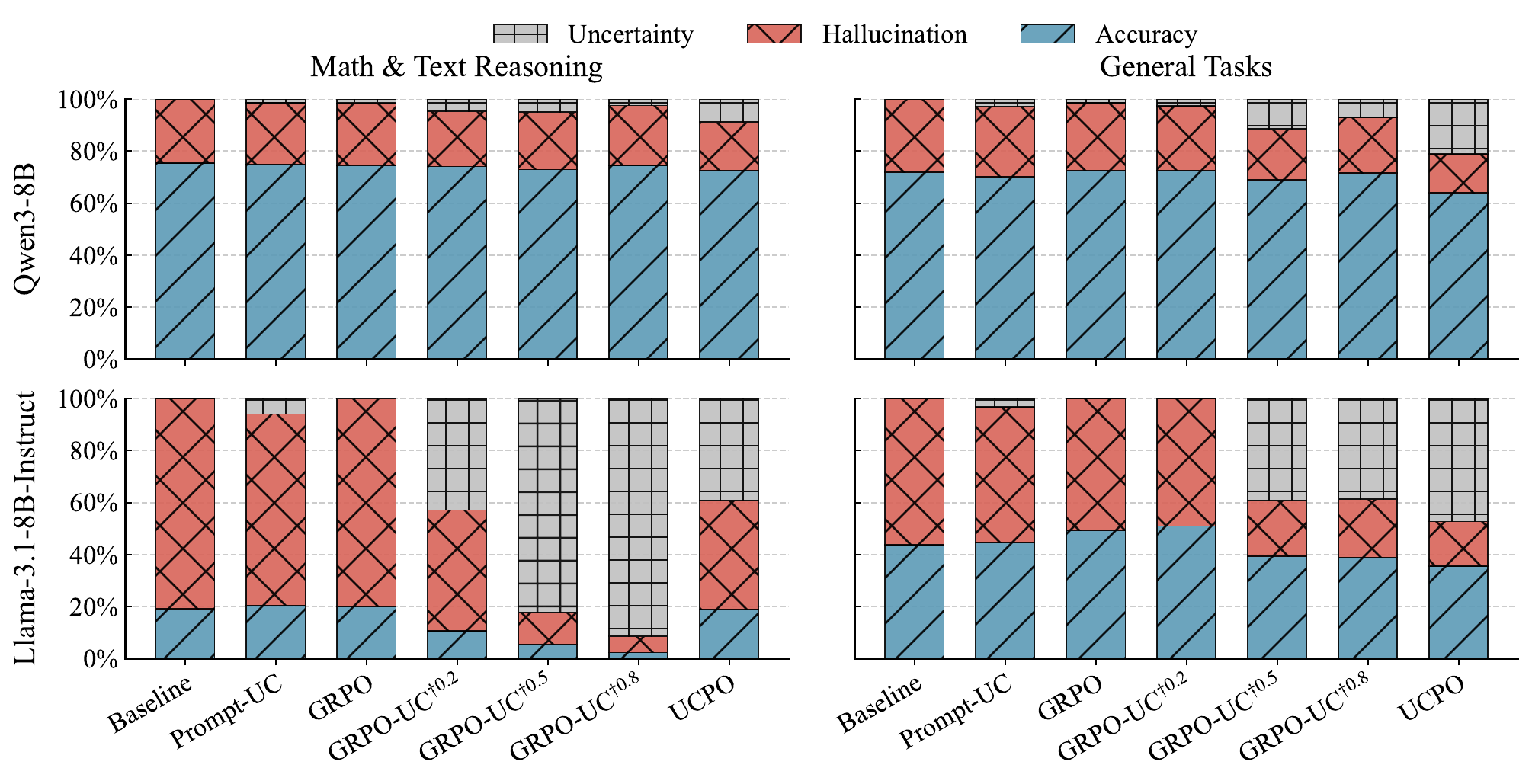
Experiments use Qwen3-8B and Llama-3.1-8B-Instruct across math and general tasks. UCPO reports the highest average PAQ in both domains for both models: for example, Qwen3-8B reaches 79.63 PAQ on math/text reasoning and 79.68 on general tasks; Llama-3.1-8B-Instruct reaches 28.45 and 58.58. The visual analyses show GRPO staying near zero uncertainty, fixed GRPO-UC variants swinging between suppression and 100% uncertainty, and UCPO converging to a more controlled uncertainty ratio.